
Background:
I started learning about reactive programming with Kotlin to develop rest api last month. I have tried to cover all the important concepts which i have gone through which helped me to build a reactive rest api. If you want to learn about building reactive rest api with Kotlin this article can be a really good start for you.
Pre-requisite: Basic programming knowledge with Kotlin
In this article Iam going to cover following concepts:
1) what is reactive programming
2) why do we need it
3) Project reactor
4) Reactive Stream api
5) Mono and Flux
6) operations on reactive streams
i) filter, map, flatmap, merge, concat, zip
7) Spring webclient
8) Project set-up for making reactive rest api
9) Music listener project
1. What is Reactive programming?
If you are coming from IT background you might have heard of procedural programming, object-oriented programming, but what is this reactive programming? “Reactive” from the name, you might have guessed that it is related to some reaction for some action/events happened. If you guessed so, you are pretty right.
According to Wikipedia, “reactive programming is a declarative programming paradigm concerned with data streams and the propagation of change. With this paradigm, it’s possible to express static (e.g., arrays) or dynamic (e.g., event emitters) data streams with ease.” So in short it’s programming which deals with asynchronous data streams.
Reactive programming deals with developing non-blocking and event-driven applications built around asynchronous data streams(will see in detail about these terms in features section) . In reactive programming, events, notification and HTTP requests are represented as data streams and applications are built to handle such streams.
Features of Reactive Programming
1) It is new Programming Paradigm
2) It is Asynchronous and non blocking
- In synchronous way, the program will wait for previous lines of codes to get executed(database call, or api call) so the next line can get executed, so thus block the main thread and make our application slower.
- In asynchronous way of programming the code will not wait for the previous lines of code to get executed (for heavy operation like getting a response from api, or database, It will happen in background) and continue executing the other codes. Whenever the response from api or database is received it will process it. Thus it doesn’t block our main thread.
Let understand with an example:
Suppose there is an application, let’s say twitter’s login functionality. Client(user) enters username and password and in background app makes get request to server to display homepage for that user after validating user details. Suppose there are limited number of thread in thread pool (say 20). So lets see how traditional rest api deals with user request, and how reactive programming really helps in scaling.
case 1) traditional rest api without reactive programming

In traditional rest api without reactive programming when a client makes request, one thread is assigned to that request and it goes to db and fetch the data. Until and unless response is not received it will wait. Once response is received it will send the response to client.
So this thread after complete execution of request get freed. If another user make a request at same time another thread get assigned to it as thread 1 is busy. So if there are 20 concurrent users all 20 threads in our thread pool get utilised. And if there comes 21st request at same time, it has to wait because all threads are busy.
case 2) with reactive programming

In Rest api built with reactive programming, when a client makes request, one thread is assigned to that request and it goes to db for fetching the data, but it will not wait for data to be received. It will send an event to database and whenever response is received it will be handled by available threads. This thus delegate the db operation, and thread doesn’t have to wait for response from db and is free to handle another request. So with minimum no. of threads in thread pool the application still can handle multiple simultaneous requests. Thus Reactive programming is asynchronous and non blocking.
3) It follows functional style code (like java 8 stream api)
Reactive programming supports functional style of coding similar to java 8 stream API.
Functional programming is a programming paradigm where programs are constructed by applying and composing functions. Functional programming technique makes our code more concise, readable and predictable. It is easy to test and maintain code developed through functional programming.
lets see with an example. This is how code looks like in functional programming. Here we are trying to get playlist by playlistId. It is going in playlistRepository and finding playlist by id. If result is received it will be returned as Mono<Playlist>. Just ignore the Mono for now, just see it’s returning playlist. If result is empty it will go in switchIfEmpty and show the error message Playlist with playlist id not found.
fun getPlaylistById(playlistId: Int): Mono<Playlist> {
return playlistRepository
.findById(playlistId)
.switchIfEmpty(
Mono.error(NotFoundException("Playlist with playlist id : $playlistId not found"))
)
}4) Data flow as event driven stream:
It ishelpful when realtime data is needed or streaming the data. Like weather data, or fifa/cricket world cup score, it keep getting updated. So whenever a new data is added in database the event is triggered and data is displayed/sent as response. It is possible with onNext() method of reactive stream api which we will look in Reactive stream api part.
5) Backpressure on data stream
Traditionally if you ask for data from database and it send lots of data, sometime your application get crashed due to out of memory error. But with reactive programming you can add limitation on no. of data being received. Due to the non-blocking nature(not blocking the threads) of Reactive Programming, the server doesn’t send the complete stream (data) at once. It can push the data concurrently as soon as it is available.
2. Why Reactive programming
1) Smooth user experience : Because data flow as event driven stream and it is asynchronous and non blocking.
2) Keep main thread free : Async work doesn’t stop/block main thread
3) Do asynchronous work in background
4) Make application responsive : because it is asynchronous and data flow is event driven
5) It provides back-pressure support
6) more cleaner and readable code because of functional programming
3. Spring, Spring WebFlux and Project Reactor
If you don’t know about spring and spring boot, spring is the most popular application development framework of Java and spring boot is module of spring that helps in building standalone applications and restful services.
The spring web framework has spring web-mvc framework which is based on thread pools. The reactive stack web framework has Spring WebFlux framework which is based on event-loop mechanism and is non-blocking, asynchronous, provides back pressure support.
Spring Framework 5 supports reactive application development by using Reactor internally and has tools for building reactive REST servers. Spring Webflux uses Reactor as the library to achieve reactive programming. Reactor is a fourth-generation reactive library, based on the Reactive Streams specification, for building non-blocking applications on the JVM. Reactor supports non-blocking backpressure by default. Reactor offers two reactive and composable Api’s Flux and Mono to work on data streams (we will see about flux and mono in detail in next section).
So we will be using Spring Webflux (which is internally using reactor) along with Kotlin to develop reactive rest apis.
4. Reactive Stream API
Java 9 introduced the reactive streams api. Reactive stream is standard specification for processing asynchronous data stream with non-blocking backpressure. It is based on Publisher-Subscriber model and have 4 interfaces:
- Publisher
2. Subscriber
3. Subscription
4. Processor
a) Publisher
Publisher is server or database i.e provider of data as events and it process and publish them to subscribers when subscribers subscribe to it. Publisher interface has one method subscribe.
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}b) Subscriber
Subscriber receive/consume events from Publisher. It has 4 methods to deal with events received.
i) onSubscribe(Subscription s): It gets called automatically when publisher registers itself after Subscriber calls subscribe. Publisher send Subscription event in this method telling that your subscription is successful.
ii) onNext(T t) : In each data transfer from publisher to subscriber onNext method is called. If publisher publish 5 events, onNext will be called 5 times.
iii) onError(Throwable t): if there is any error in event processing this method is called.
iv) onComplete() : if there is no error in event processing and all event are successfully completed this method is called.
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}c) Subscription
It represents unique relationship between a Subscriber and a Publisher. It has 2 methods — request and cancel. Subscriber will call request and cancel methods to get data from publisher and cancel receiving data from publisher respectively.
public interface Subscription {
public void request(long n);
public void cancel();
}d) Processor
Processor represents processing stage that consists of both Publisher and Subscriber.
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
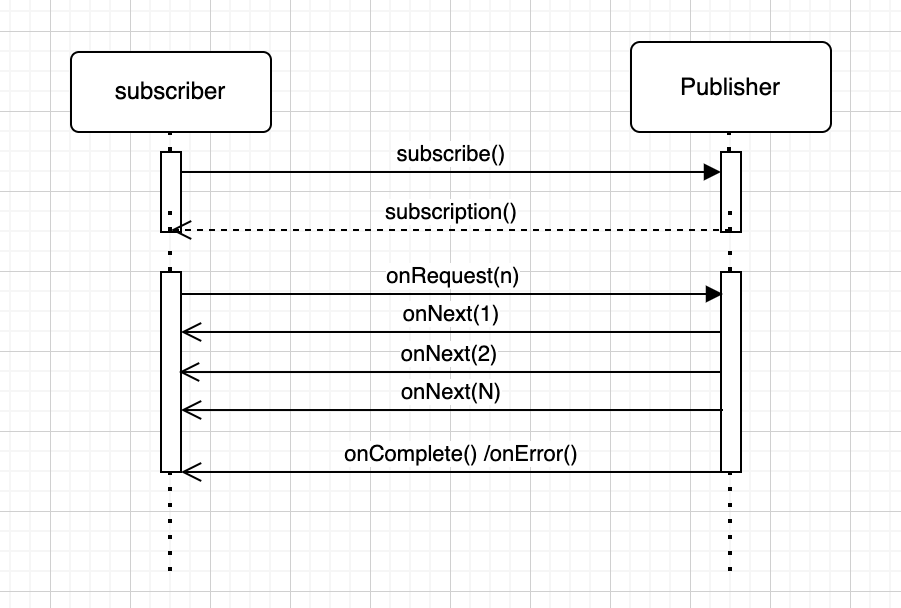
}So, the reactive stream workflow looks like as shown below:

i) First subscriber need to register to the publisher by calling the subscribe() method
ii) Publisher then sends subscription event to the subscriber and onSubscribe() method of subscriber is called
iii) Then subscriber request data from the publisher (he can request n no. of data) using request(n) method
iv) then publisher will publish data as data streams by calling onNext() event method. For n no of events/records onNext() method will be called n number of times.
v) then on completion publisher will fire onComplete() event. If any error occurs in between onError() event will be called.
5. Mono and Flux
Mono and Flux are reactive types that implement Publisher. A flux object represents a reactive sequence of 0 to N items while a Mono object represents of 0 or 1 item in result.
a) Flux:
A Flux<T> (where T is type of Flux i.e data, it can be Integer, a class or anything) is a standard publisher that represents an asynchronous sequence of 0 to N items. The reactive stream specification methods are applicable on this as well (those which are applicable or called by publisher that we have seen in reactive stream workflow i.e onNext, onComplete, onError). We use flux when we are expecting 0 to N number of data from server. For example if we are making a get request to fetch all songs from server i.e we are expecting 0 to N number of song object as response, at that time we will use Flux.
Creating flux :
//creating a Flux allSongs of String type
val allSongs = Flux.just("lullaby", "sugar and brownies", "brightest light")
//as a subscriber we will subscribe the allSongs flux to get the data streams from producer.
//with this code we have subscribe to Publisher
allSongs.subscribe()
//if we want to print each element we can do that with help of lambda
allSongs.subscribe({ song -> println(song)}) //lullaby, sugar and brownies, brightest light
//if there occurs error in between we can handle that as well as follows
allSongs.subscribe({ song -> println(song)},
{ error -> println("error is $error")}) There is .log() method which we can use to trace and observe all stream signals. The events are logged into the console.

other operation on flux, we will see in next section.
b) Mono:
A Mono<T> (where T is type of Mono, it can be Integer, a class or anything) is a specialised publisher that emits atmost one item. The reactive stream specification methods are applicable on this as well (those which are applicable or called by publisher that we have seen in reactive stream workflow i.e onNext, onComplete, onError). There will be atmost one onNext signal call because atmost one item is there. onComplete() signal will be emitted if successfully data is processed and transmitted else onError signal will be emitted. We use Mono when we are expecting atmost one data from server. For example if we are making a get request to fetch a song with song_id = 1 then from server we are expecting either 0(song not present) or 1 song object as response, at that time we will use Mono.
//creating a Mono of a song
val song = Mono.just("on my way")
//we need to subscribe to stream of data so producer start emitting elements
song.subscribe()
//if we want to print each element we can do that with help of lambda
song.subscribe({ songName -> println(songName)}) //on my way
//if there occurs error in between we can handle that as well as follows
song.subscribe({ songName -> println(songName)},
{ error -> println("error is $error")})other operation on mono, we will see in next section.
6. Operations on reactive streams
Reactor provides operators to work with Mono and Flux objects. Some of them are filter, map, flatmap, merge, concat, zip.
i) filter : It is used to filter a sequence. For example if you have a Flux of list of numbers [1,2,3,4,5,6] and you want to filter all numbers that are even, then we can use filter. The code for same is shown below:
val numbers = Flux.just(1,2,3,4,5,6)
val evenNumbers = numbers.filter({ num -> num % 2 == 0 })
evenNumbers.subscribe({ num -> println(num) }) // 2,4,6
//or all 3 lines can be combined as follows
Flux.fromIterable(listOf(1,2,3,4,5,6))
.log()
.filter { value -> value % 2 == 0 }
.subscribe({value -> println(value) }) // output -> 2,4,6ii) map : It is used to transform existing sequence on 1-to-1 basis. For example if you have a Flux of list of numbers [1,2,3,4,5,6] and you want to square all numbers, then we can use map. The code for same is shown below:
val numbers = Flux.just(1,2,3,4,5,6)
val squaredNumbers = numbers.map { num -> num*num }
squaredNumbers.subscribe({ num -> println(num) }) //1,4,9,16,25,36
//or all 3 lines can be combined as follows
Flux.fromIterable(listOf(1,2,3,4,5,6))
.log()
.map{ num -> num*num }
.subscribe({ value -> println(value) }) //1,4,9,16,25,36iii) flatMap: It is used to transform existing sequence on 1-to-n basis. It transforms the elements emitted by Flux/Mono asynchronously into Publisher, then flatten these inner publishers into single Flux through merging. So basically for asynchronous operation on emitted elements flatMap is used. For example if we have flux of list of numbers which is nothing but list of songids and we want to get song corresponding to every song id by making a database call (which is asynchronous) then we will use flatMap. The code for same is shown below:
fun fluxFlatMap() {
val songsId = Flux.just(1,2,3,4,5,6)
val songsNames = songsId.flatMap({ id -> getSongName(id) })
songsNames.subscribe({ song -> println(song) })
//or all 3 lines can be combined as follows
Flux.fromIterable(listOf(1,2,3,4,5,6))
.log()
.flatMap{ id -> getSongName(id) }
.subscribe({ song -> println(song) })
}
private fun getSongName(id: Int?): Mono<String> {
val songs = mapOf(
1 to "pink venom",
2 to "nobody",
3 to "passionfruit",
4 to "nevermind",
5 to "this time"
)
Thread.sleep(3000);
return songs.getOrDefault(id, "not found").toMono()
}output:
iv) merge : It is used to combine multiple reactive streams(publishers) without maintaining the sequence of the publisher. If two flux of list of elements are [1,2,3,4,5] and [11,12,13,14,15] and while receiving them there is delay in fetching individual elements then on merge(list1,list2) sequence don’t necessarily to be in order like [1,2,3,4,5,11,12,13,14,15].
val list1 = Flux.just(1, 2, 3, 4, 5, 6)
val list2 = Flux.just(11, 12, 13, 14, 15, 16)
val mergedList = Flux.merge(list1, list2)
mergedList.subscribe { num -> println(num) }v) concat: It is used to combine publisher by maintaining the sequence of the publisher. If two flux of list of elements are [1,2,3,4,5] and [11,12,13,14,15] and while receiving them there is delay in fetching individual elements then on concat(list1,list2) sequence will be in order like [1,2,3,4,5,11,12,13,14,15].
val list1 = Flux.just(1, 2, 3, 4, 5, 6)
val list2 = Flux.just(11, 12, 13, 14, 15, 16)
val mergedList = Flux.concat(list1, list2)
mergedList.subscribe { num -> println(num) }vi) zip : zip is used to combine multiple publishers by waiting on all sources to emit one-one element and then combine them in output tuple. For example if we have two flux [A,B,C,D] and [1,2,3,4] then the combined flux with zip will have [ [A,1], [B,2], [C,3], [D,4] ].

code:
val list1 = Flux.just("hello" , "hi", "hola")
val list2 = Flux.just("jsx", "kt", "java")
val result = Flux.zip(list1, list2)
result.subscribe { tuple -> println(tuple) }
/*
output:
[hello,jsx]
[hi,kt]
[hola,java]
*/
7. Spring WebClient
WebClient is a reactive web client introduced in spring 5. Those who don’t know, WebClient is an application program that communicated with web browser using http protocol. So WebClient is a non blocking client for making http requests. It is used if you want to interact with some other application and make a http call to get or post data from your application. For example if you have a music listener application where you can play particular song, add song to playlist or delete songs from it, but the songs are coming from some other api, we want to call that api to get the song to add them to playlist or see it details, in that case we will use spring webclient to make http request. So it is main entry point for performing web requests. It offer support for both synchronous and asynchronous operation. We will see hands-on with project on how we can use webclient to make http calls in next article.
—
So, this is all for this article. In this article we have seen what is reactive programming, what are it’s features and benefits, what is Project reactor, what is Reactive Stream api, what are Mono and Flux and how to create it and how to do various operations on reactive streams like filter, map, flatmap, merge, concat, zip. At the end we have seen what is Spring webclient.
In next article we will see how to setup the project, how to create a reactive rest api with Kotlin and spring webflux, how to make http calls using webclient by creating a music player and music listener application.
Thanks a lot for reading this. Hope you get a brief idea about reactive programming.

{kind=link}